[데이터분석] 데이터 크롤링 실습(2) - 인프런 크롤링
2024. 8. 14. 00:17ㆍAI & DS/머신러닝
오늘은 인프런 사이트의 데이터 크롤링 실습을 진행하여 보도록 하겠습니다
DataCrawling Pycharm Library Setting
import selenium
print(selenium.__version__)
from selenium import webdriver
from selenium.webdriver.common.by import By
import sys
from selenium.webdriver.common.keys import Keys
import urllib.request
import os
from urllib.request import urlretrieve
import time
import pandas as pd
import numpy as np
import re # 전처리를 위한 라이브러리
chrome_options = webdriver.ChromeOptions()
chrome_options.add_argument('--headless') # ensure GUI is off
chrome_options.add_argument('--no-sandbox')
chrome_options.add_argument('--disable-dev-shm-usage') # set path to chromedriver as per your configuration
chrome_options.add_argument('lang=ko_KR') # 한국어
chrome_options.add_argument('user-agent=Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, '
'like Gecko) Chrome/91.0.4472.124 Safari/537.36')
# selenium driver 로드
driver = webdriver.Chrome(options=chrome_options)
- library Setting을 위한 코드의 수가 많기 때문에 dataCrawlingSetting.py 이라는 파일에 setting값을 설정해 준뒤, 다른 파일을 생성한 경우, from dataCrawlingSetting import * 해주는 방식을 사용하였습니다.

사이트 파악하기
- 먼저 인프런 사이트에 접속하여 한 강의 페이지를 띄워보겠습니다

- 개발자 도구를 켜 제목위에 커서를 놓으니 매우 긴 태그 이름을 가진 것을 알 수 있습니다. 이 경우 “아 크롤링하기 빡세겠구나!”라는 뜻으로 받아들이면 됩니다.
- 어느 정도 인코딩을 통해 암호화 했음
- 코드화 시킴
- 목적성을 숨김
- 무엇을 하고 있는 지 드러나지 않음
- 랜덤화하여 지속적으로 바꿈
- ⇒ 서버에 과부화를 주는 것을 막음
즉, 인프런 사이트의 개발자 왈 “크롤링 허용은 하겠으나, 너무 무분별하게 가져가진 마라!” 라고 이야기하고 있는 것 입니다.
내부 페이지 크롤링 하기
- #CSS_SELECTOR를 활용해서 div 태그를 가져오기

# 복사하면 가져와지는 형태
div = driver.find_element(By.CSS_SELECTOR, "div.css-rwn1m mantine-1jggmkl")
# 크롤링 시 클래스명에서 띄어쓰기는 .으로 변경해 주는 것이 좋음
div = driver.find_element(By.CSS_SELECTOR, "div.css-rwn1m.mantine-1jggmkl")
div 태그 영역에 속해있는 정보들을 가져와 보겠습니다.
따라서, 식의 형태는 div.find_element() 가 되어야합니다.
- 제목 가져오기

title = div.find_element(By.CSS_SELECTOR, "h1.mantine-Text-root.mantine-Title-root.css-1m4c0vr.mantine-17uv248")
print(title.text.split('\\n')[0])
- .text : text만 뽑아서 print하는 함수
- split: 정규표현식 라이브러리 함수 중 하나로, 아래에서 정규표현식 라이브러리 함수의 종류와 사용법을 참고로 알아보도록 하겠습니다.
- cf) 정규표현식 라이브러리 함수 사용법
- Match: 문자열 처음부터 정규식과 매칭되는 패턴을 찾아서 리턴
- Search : 문자열 전체를 검색해서 정규식과 매칭되는 패턴을 찾아서 리턴
- Findall : 정규표현식과 매칭되는 모든 문자열을 리스트 객체로 리턴
- Split : 찾은 정규표현식 패턴 문자열을 기준으로 문자열을 분리
- Sub : 찾은 정규표현식 패턴 문자열을 다른 문자열로 변경
- cf) 정규표현식 라이브러리 함수 사용법
- 평점 및 리뷰 수/ 수강생 수/ 강사 이름 : 단일 요소 가져오기 find_element
#평점 및 리뷰 수 가져오기
star_Reviews = div.find_element(By.CSS_SELECTOR, "a.mantine-Text-root.mantine-ugy335")
print(re.findall(r"\\d.\\d", star_Reviews.text)[0])
print(re.findall(r"\\d*개", star_Reviews.text)[0].split('개')[0]) #regex
# 수강생 수 가져오기
students_num = div.find_element(By.CSS_SELECTOR, "p.mantine-Text-root.mantine-1nvrx8e")
print(re.findall(r"\\d.*명", students_num.text)[0].split('명')[0])
# 강사 이름 가져오기
lecturer_name = div.find_element(By.CSS_SELECTOR, "a.mantine-Text-root.mantine-vsq1iu")
print(lecturer_name.text)
- 태그 가져오기 : 여러 요소 가져오기 find_elements & for-each문
# 태그 가져오기
tags = div.find_elements(By.CSS_SELECTOR, "a.mantine-Badge-root.mantine-1ojzf7r")
for tag in tags:
print(tag.text)
- 가격 가져오기 : 여러 case 별로 나누어 가져오기 try-except문
- 가격은 판매가, 할인율, 정가, 분할납부 등 강좌별로 여러가지 종류로 나뉘기 때문에 try-except문을 사용해 case를 나누어 주어야한다.
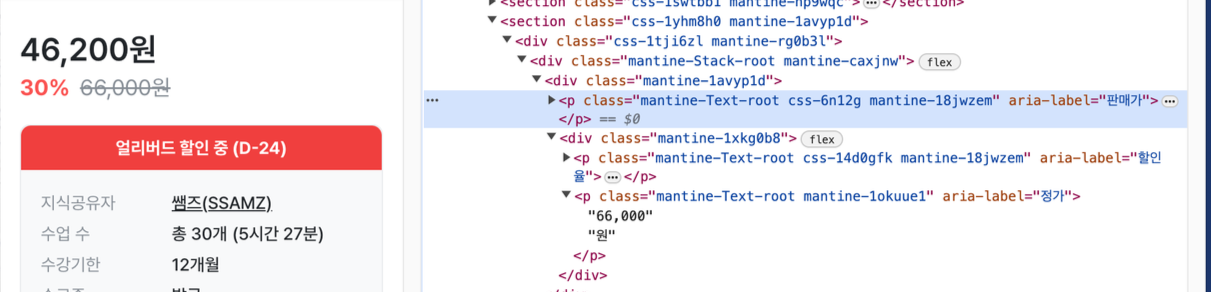
# 가격 가져오기
try: # 할인이 없는 경우
price = driver.find_element(By.CSS_SELECTOR, 'p.mantine-Text-root.css-6n12g.mantine-18jwzem[aria-label="정가"]')
price_text = price.text.split('원')[0].replace(',', '')
price_int = int(price_text)
print(price_int)
except:
try: # 할인이 있는 경우
price = driver.find_element(By.CSS_SELECTOR, 'p.mantine-Text-root.mantine-1okuue1[aria-label="정가"]')
price_text = price.text.split('원')[0].replace(',', '')
price_int = int(price_text)
print(price_int)
except:
try: # 분할 납부가 가능한 경우
price = driver.find_element(By.CSS_SELECTOR, 'p.mantine-Text-root.mantine-j1a4p1')
price_text = price.text.split('원')[0].replace(',', '')
price_int = int(price_text)
print(price_int)
except:
try: # 할인이 있는 경우 2
price = driver.find_element(By.CSS_SELECTOR, 'p.mantine-Text-root.css-141ggaf.mantine-18jwzem[aria-label="정가"]')
price_text = price.text.split('원')[0].replace(',', '')
price_int = int(price_text)
print(price_int)
except:
print("가격이 없습니다.")
- 찜하기 가져오기
- copy selector : 딱 해당 element를 가져올 때 유용하다.

# copy selector를 가져온 후 수정하기
#__next > main > section:nth-child(2) > div > div > div.mantine-SimpleGrid-root.mantine-1dfaauk > button:nth-child(2)
heart = driver.find_element(By.CSS_SELECTOR, "div.mantine-SimpleGrid-root.mantine-1dfaauk > button:nth-child(2) > div > span.mantine-1bvbs5e.mantine-Button-label")
print(heart.text)
- 강의 수 및 총 시간 가져오기
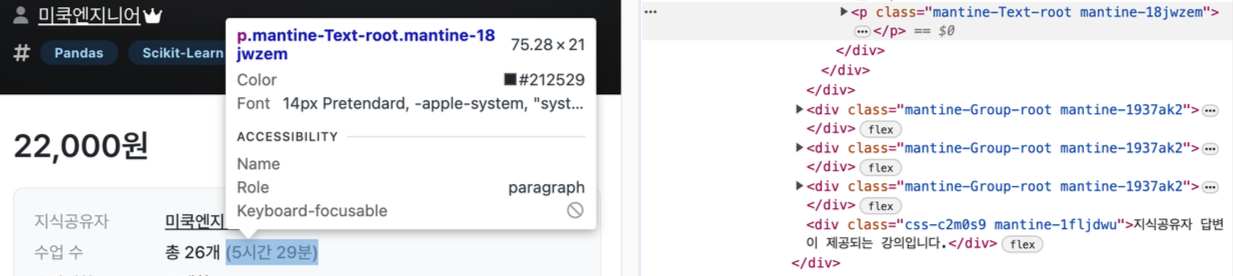
# 강의 수 및 총 시간 가져오기
lec_len_info = driver.find_element(By.CSS_SELECTOR, "div.mantine-Group-root.mantine-1n7ftt8")
print(re.findall("\\d*개", lec_len_info.text)[0].split('개')[0])
print(re.findall("\\(.*\\)", lec_len_info.text)[0].replace("(", "").replace(")", ""))
#driver 종료
driver.quit()
함수로 만들기
- 매개변수로 url을 받아주고, 수집한 정보는 dictionary로 저장하여 return하는 함수로 만들어보자.
import re
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.chrome.options import Options
import numpy as np
def scrape_course_info(url):
driver = webdriver.Chrome(options=chrome_options)
driver.get(url) # 매개변수로 url를 받아서
div = driver.find_element(By.CSS_SELECTOR, "div.css-rwn1m.mantine-1jggmkl")
course_info = {} # 정보 저장을 위한 딕셔너리 초기화
title = div.find_element(By.CSS_SELECTOR, "h1.mantine-Text-root.mantine-Title-root.css-1m4c0vr.mantine-17uv248")
course_info['title'] = title.text.split('\\n')[0]
star_Reviews = div.find_element(By.CSS_SELECTOR, "a.mantine-Text-root.mantine-ugy335")
course_info['rating'] = re.findall("\\d.\\d", star_Reviews.text)[0]
course_info['num_reviews'] = re.findall("\\d*개", star_Reviews.text)[0].split('개')[0]
num_students = div.find_element(By.CSS_SELECTOR, "p.mantine-Text-root.mantine-1nvrx8e")
course_info['num_students'] = re.findall("\\d.*명", num_students.text)[0].split('명')[0]
lecturer_name = div.find_element(By.CSS_SELECTOR, "a.mantine-Text-root.mantine-vsq1iu")
course_info['lecturer'] = lecturer_name.text
tags = div.find_elements(By.CSS_SELECTOR, "a.mantine-Badge-root.mantine-1ojzf7r")
course_info['tags'] = [tag.text for tag in tags]
try: # 할인이 없는 경우
price = driver.find_element(By.CSS_SELECTOR, 'p.mantine-Text-root.css-6n12g.mantine-18jwzem[aria-label="정가"]')
price_text = price.text.split('원')[0].replace(',', '')
price_int = int(price_text)
except:
try: # 할인이 있는 경우
price = driver.find_element(By.CSS_SELECTOR, 'p.mantine-Text-root.mantine-1okuue1[aria-label="정가"]')
price_text = price.text.split('원')[0].replace(',', '')
price_int = int(price_text)
except:
try: # 분할 납부가 가능한 경우
price = driver.find_element(By.CSS_SELECTOR, 'p.mantine-Text-root.mantine-j1a4p1')
price_text = price.text.split('원')[0].replace(',', '')
price_int = int(price_text)
except:
try: # 할인이 있는 경우 2
price = driver.find_element(By.CSS_SELECTOR, 'p.mantine-Text-root.css-141ggaf.mantine-18jwzem[aria-label="정가"]')
price_text = price.text.split('원')[0].replace(',', '')
price_int = int(price_text)
except:
price_int = np.nan
course_info['price'] = price_int
heart = driver.find_element(By.CSS_SELECTOR, "div.mantine-SimpleGrid-root.mantine-1dfaauk > button:nth-child(2) > div > span.mantine-1bvbs5e.mantine-Button-label")
course_info['hearts'] = heart.text
lec_len_info = driver.find_element(By.CSS_SELECTOR, "div.mantine-Group-root.mantine-1n7ftt8")
course_info['num_lectures'] = re.findall("\\d*개", lec_len_info.text)[0].split('개')[0]
course_info['total_time'] = re.findall("\\(.*\\)", lec_len_info.text)[0].replace("(", "").replace(")", "")
driver.quit()
return course_info
# 예시 사용법
course_info = scrape_course_info("<https://www.inflearn.com/course/%EB%B9%85%EB%8D%B0%EC%9D%B4%ED%84%B0-%EB%B6%84%EC%84%9D%EA%B8%B0%EC%82%AC-%EC%8B%A4%EA%B8%B0#curriculum>")
print(course_info)
강의 링크 리스트 가져오기
- a 태그는 여러 곳에서 사용되고 있기 때문에, a 태그만으로 강의 링크 리스트를 가져오기에는 위험성이 있다.
- 따라서, 보다 확실한 넓은 범위의 section 태그를 먼저 가져오고 거기에 속해있는 강의 리스트 a 태그들을 사용하여 크롤링하는 방식을 취한다.
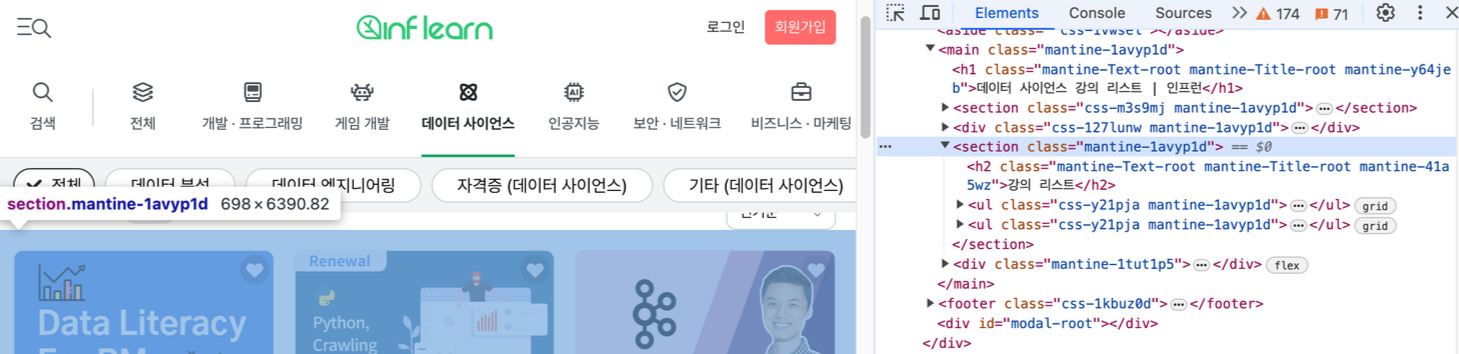

import re
#selenium driver 로드
driver = webdriver.Chrome(options=chrome_options)
#URL 정보를 받을 리스트
url_list = []
#링크 전달
for i in range(1, 10): # 1~10페이지에 대해서
driver.get(f"<https://www.inflearn.com/courses/data-science?sort=POPULAR&page_number={i}>")
#CSS_SELECTOR를 활용해서 section 태그를 가져오기
section = driver.find_element(By.CSS_SELECTOR, "section.css-18qnvtf.mantine-1avyp1d")
a_tags = section.find_elements(By.TAG_NAME, "a")
# 리스트를 저장하는 방식 중 하나
hrefs = [a.get_attribute("href") for a in a_tags if a.get_attribute("href")]
#driver 종료
driver.quit()
리스트에 대해서 각각 크롤링 해오기
# tqdm : 진행률을 표시하는 것
from tqdm import tqdm
course_info_dicts = list()
# hrefs를 tqdm으로 감싸서 진행률 표시줄을 추가합니다.
for href in tqdm(hrefs, desc="Scraping course info"):
try:
course_info_dict = scrape_course_info(href)
course_info_dicts.append(course_info_dict)
except:
pass
- tqdm : 진행률을 표시하는 것DataCrawling Pycharm Library Setting
엑셀파일로 저장하기
inflearn_df = pd.DataFrame(course_info_dicts)
inflearn_df.to_excel("inflearn_df_240702.xlsx")
inflearn_df
'AI & DS > 머신러닝' 카테고리의 다른 글
| [머신러닝] 주식 종목 추천 시스템 - (2) 데이터 수집 (0) | 2024.08.14 |
|---|---|
| [머신러닝] 주식 종목 추천 시스템 - (1) yfinance 라이브러리 설치 & Ticker란? (0) | 2024.08.14 |
| [데이터분석] 데이터 크롤링 실습(1) (0) | 2024.08.14 |
| [데이터분석] 데이터 크롤링 (0) | 2024.08.14 |
| [머신러닝] - 머신러닝의 개념 및 종류 (0) | 2024.08.13 |