2025. 5. 15. 18:36ㆍAI & DS/딥러닝
최근 몇 년 사이 AI가 생성한 이미지들이 사람의 손으로 그린 그림과 구분하기 어려울 만큼 정교해졌습니다.
그 중심에는 Diffusion Model이라는 생성 모델이 존재합니다.
특히, 이 모델을 효율적으로 구현한 Stable Diffusion, 그리고 이를 구조적으로 제어할 수 있도록 도와주는 ControlNet은 현재 가장 주목받는 기술 중 하나입니다.
Diffusion Model: 노이즈를 통한 생성
Diffusion Model은 데이터 생성 과정을 정확히 반대로 생각하는 발상에서 시작합니다.
Forward Process

이 모델은 원래 존재하는 이미지를 점차 노이즈로 오염시키는 과정을 먼저 정의합니다. 이 과정을 Forward Process라고 하며, 수학적으로는 각 시간 t마다 조금씩 가우시안 노이즈를 추가해, 결국 완전히 무작위한 노이즈 이미지로 만드는 방식입니다.
Reverse Process

하지만 우리가 진짜 원하는 건 Reverse Process, 즉 노이즈에서 시작해 점점 선명한 이미지로 복원해 나가는 과정입니다. 이 역과정은 실제로 모델이 학습해야 하는 부분이며, 대부분의 Diffusion Model은 각 단계에서 노이즈를 예측하는 U-Net 기반의 신경망을 통해 이를 수행합니다. 이 과정은 일종의 denoising score matching 문제로 볼 수 있으며, 모델은 다양한 시간 스텝에서 노이즈를 얼마나 잘 제거할 수 있는지를 학습하게 됩니다.
Stable Diffusion
Stable Diffusion은 전통적인 diffusion 방식에 두 가지 핵심 아이디어를 더해 성능과 속도를 크게 개선한 모델입니다.
1. 잠재(latent space)에서 diffusion 수행

첫째, 이 모델은 고해상도 이미지 전체가 아닌 잠재 공간(latent space)에서 diffusion을 수행합니다.
Stable Diffusion은 Latent Diffusion Model(LDM) 아키텍처를 기반으로 합니다. 이는 이미지 생성 과정을 고차원 픽셀 공간이 아닌 저차원 잠재 공간에서 수행하여 계산 효율성을 높이는 방식입니다.
- VAE를 통한 이미지 압축: 입력 이미지는 VAE의 인코더를 통해 잠재 공간으로 압축됩니다. 이 과정에서 이미지의 주요 특징이 저차원 벡터로 표현되어, 이후의 처리 과정이 간소화됩니다.
- 잠재 공간에서의 노이즈 제거: 압축된 잠재 표현에 노이즈를 추가하고, 이를 제거하는 과정을 반복하여 최종 이미지를 생성합니다. 이러한 방식은 고차원 이미지 공간에서 직접 처리하는 것보다 훨씬 효율적입니다.
- 디코더를 통한 이미지 복원: 노이즈가 제거된 잠재 표현은 VAE의 디코더를 통해 다시 고해상도 이미지로 복원됩니다.
이러한 구조는 계산 자원을 절약하면서도 고품질의 이미지를 생성할 수 있도록 합니다.
2. CLIP의 텍스트 인코더 사용
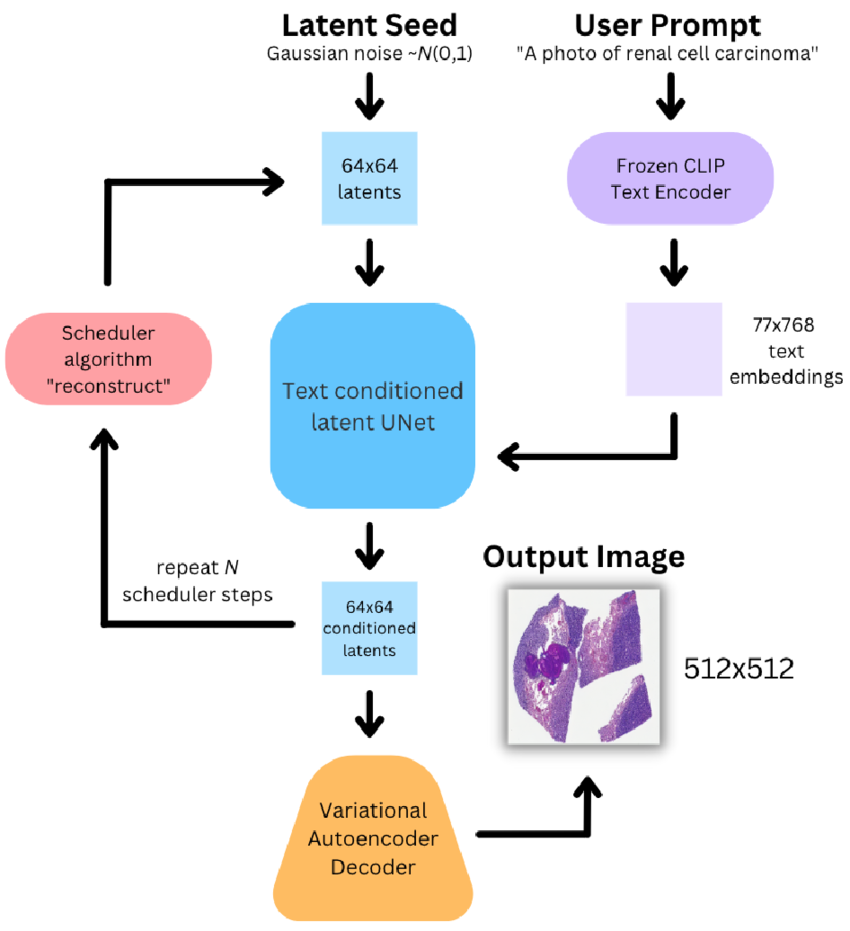
둘째, 텍스트 조건을 반영하기 위해 CLIP의 텍스트 인코더를 사용합니다. 이 텍스트 임베딩은 U-Net의 각 attention layer에 Cross-Attention 형태로 삽입되어, 모델이 “무엇을 그릴 것인지”를 이해하도록 합니다. 예를 들어, “A cat playing piano”라는 텍스트가 입력되면, latent noise에서 시작한 U-Net은 점차 그 텍스트 의미에 맞는 이미지를 복원해냅니다.
Stable Diffusion은 결과적으로 Text → Latent Noise → U-Net(Denoising) → VAE Decoder → Image라는 구조를 따르며, 기존 diffusion model보다 빠르고 가벼우면서도 높은 품질의 이미지를 생성할 수 있습니다.
ControlNet이란?
Stable Diffusion은 창의적인 이미지를 생성할 수는 있지만,구체적인 구조나 구도를 정밀하게 제어하긴 어렵습니다. 예를 들어 사람의 포즈나 스케치를 그대로 반영한 이미지를 만들고 싶을 때, 텍스트만으로는 한계가 있습니다. 이를 해결하기 위해 등장한 기술이 바로 ControlNet입니다.
ControlNet은 기본적으로 Stable Diffusion의 U-Net 구조를 확장한 형태입니다. 기존의 U-Net은 latent noise만을 입력받지만, ControlNet은 여기에 추가적으로 외부 구조 정보(예: 포즈맵, 윤곽선, depth map 등)을 입력받아, 이를 기반으로 더 정확한 생성 결과를 만들어냅니다.
ControlNet의 구조는 복사된 U-Net을 기반으로 하며, 해당 네트워크는 보통 freeze된 상태로 시작합니다. 그리고 그 위에 몇 개의 학습 가능한 계층을 추가하여, 입력된 구조 정보가 본 모델에 영향을 주도록 만듭니다.
특히 이 과정에서는 Zero Convolution 기법을 통해 초기에는 영향을 거의 주지 않도록 하며, 학습이 진행되면서 점점 구조 정보가 이미지 생성에 영향을 주도록 조정됩니다. 이렇게 하면 기존 모델의 성능을 해치지 않으면서, 구조를 제어하는 능력만 덧붙일 수 있게 됩니다.
예를 들어 ControlNet에 “사람이 점프하는 포즈맵" 이미지와 “a girl jumping in the air”라는 텍스트를 동시에 입력하면, 결과물은 해당 포즈를 충실히 반영하면서도 텍스트 의미를 담은 이미지가 됩니다.
ControlNet Scribble with Diffusers

Scribble 기반 ControlNet 구조와 원리
ControlNet이 Scribble(낙서) 형태의 입력을 받을 때, 그 구조가 어떻게 작동하고 Stable Diffusion과 어떻게 연결되어 있는지를 상세히 설명드리겠습니다.
ControlNet - Scribble 은 어떻게 동작하는가?
ControlNet은 기존 Stable Diffusion의 이미지 생성 과정을 “두 겹으로 복제”하여 구성됩니다. 이때 핵심적인 개념은 크게 세 가지로 요약할 수 있습니다.
- 기존의 Stable Diffusion 모델을 그대로 사용하되 가중치를 고정(freeze)합니다.
- 동일한 구조의 학습 가능한 복제본(trainable copy)을 새로 생성해 조건 정보(예: scribble)를 학습합니다.
- 두 구조를 zero convolution layer를 통해 연결하여 새로운 조건이 기존 모델에 자연스럽게 반영되도록 합니다.
즉, ControlNet은 Stable Diffusion이라는 거대한 모델을 건드리지 않으면서, 별도의 브랜치를 만들어 추가적인 제어 능력을 부여하는 방식입니다.
Scribble은 어떻게 입력되는가?
Scribble은 말 그대로 아주 단순한 선으로 그려진 스케치나 낙서입니다. 예를 들어 여우의 실루엣을 연필로 대충 그리거나, 사람의 자세를 뼈대 형태로 선으로 표현하는 식이죠. 이러한 scribble 입력은 일반적으로 흑백(edge-like) 이미지로 표현되며, ControlNet에서는 이 이미지를 바로 조건 정보로 사용합니다.
ControlNet에서 Scribble은 별도의 Feature 추출 없이 단순히 전처리된 binary edge map 형태로만 입력됩니다. 이 간단한 조건 입력이 이미지 생성에 얼마나 강력한 영향을 주는지 이해하려면 내부 구조를 들여다볼 필요가 있습니다.
Stable Diffusion과 ControlNet의 구조 비교

ControlNet의 내부 구조는 Stable Diffusion의 latent UNet 구조를 복제한 것입니다. 그림으로 보면, 좌측에는 기존 Stable Diffusion의 U-Net이 있고, 우측에는 동일한 구조를 갖지만 학습이 가능한 ControlNet branch가 있습니다.
이 ControlNet branch는 입력된 scribble 조건을 받아 각 encoder 블록에서 독립적으로 feature를 생성하고, 이를 기존 Stable Diffusion 네트워크의 대응 블록에 전달합니다. 이 전달 과정에서 중요한 역할을 하는 것이 바로 Zero Convolution layer입니다.
Zero Convolution이란?
학습 가능한 1×1 컨볼루션 레이어지만, 초기값이 0으로 설정되어 있습니다. 초기에는 ControlNet branch에서 아무런 정보도 전달되지 않으며, 생성 결과는 기존 Stable Diffusion과 동일합니다. 하지만 학습이 진행되면서 이 레이어는 점차 활성화되어, ControlNet이 학습한 조건 정보를 기존 네트워크에 점진적으로 반영하게 됩니다.
이 방식의 가장 큰 장점은, 기존 모델이 학습한 방대한 데이터 지식(semantic prior)을 유지하면서도, 새로운 조건에 유연하게 적응할 수 있다는 점입니다.
Scribble을 이용한 이미지 생성의 흐름
Scribble을 활용한 이미지 생성 과정은 다음과 같은 단계를 거칩니다.
- 사용자 입력
- 사용자가 작성한 텍스트 프롬프트 (예: “a fantasy castle on a mountain”)
- 사용자 낙서 이미지 (예: 산 위에 간단한 선으로 그린 성 형태)
- Scribble 전처리
- 낙서 이미지를 grayscale로 변환하고, binary edge map으로 이진화
- 이 이미지가 ControlNet의 입력 condition이 됨
- ControlNet에 입력
- 이 edge map은 ControlNet의 trainable copy UNet에 전달되어 각 계층별로 구조 정보를 학습
- Cross-Attention
- CLIP text encoder로부터 생성된 텍스트 임베딩은 Stable Diffusion과 ControlNet의 Cross Attention에 활용
- Zero Conv를 통해 통합
- ControlNet의 각 블록 출력은 Zero Convolution을 통해 Stable Diffusion의 대응 블록에 전달
- Decoder + VAE 복원
- 최종 latent를 기존 VAE decoder가 픽셀 이미지로 복원
결과적으로, 생성된 이미지는 사용자의 낙서 형태와 텍스트 프롬프트를 모두 반영한 고화질 이미지가 됩니다.
모델 실습
ControlNet in 🧨 Diffusers
huggingface.co
라이브러리 설치
# 라이브러리 설치 (Google Colab 기준)
!pip install openai
!pip install diffusers transformers accelerate huggingface_hub라이브러리 임포트
# 라이브러리 임포트
import openai # ChatGPT API 호출용
import time
from diffusers import StableDiffusionControlNetPipeline, ControlNetModel, UniPCMultistepScheduler
from diffusers.utils import load_image
from transformers import AutoTokenizer
from PIL import Image
from google.colab import files # 이미지 업로드용
import torchControlNet 모델 로드
# ControlNet 모델 로드
# 사용 모델: 'lllyasviel/sd-controlnet-scribble' → Scribble(낙서) 조건을 위한 사전학습된 ControlNet
controlnet = ControlNetModel.from_pretrained(
"lllyasviel/sd-controlnet-scribble",
torch_dtype=torch.float16
)
lllyasviel/sd-controlnet-scribble
- ControlNet의 scribble 버전으로 낙서 형태의 구조(condition)를 입력으로 받아 이름 기반으로 이미지를 생성하는데 특화된 모델로, ControlNet 시리즈의 창시자인 Lvmin Zhang (aka lllyasviel)이 직접 개발한 오리지널 모델입니다.
- 입력으로 edge map이나 단순한 스케치를 받습니다.
- 주어진 구조를 최대한 보존하면서 텍스트 프롬프트의 스타일적 특성을 결합해 이미지를 생성합니다.
- 내부적으로는 Stable Diffusion v1.5의 UNet을 복제하여 제어 분기(branch)를 추가한 구조입니다.
Stable Diffusion 파이프라인 로드 + ControlNet 결합
# Stable Diffusion 파이프라인 로드 + ControlNet 결합
# 'Lykon/dreamshaper-8'는 aesthetic tuning된 고화질 프롬프트 대응 모델
pipe = StableDiffusionControlNetPipeline.from_pretrained(
"Lykon/dreamshaper-8", # 기본 이미지 생성 모델
controlnet=controlnet, # ControlNet 연결
torch_dtype=torch.float16 # GPU 메모리 절약을 위한 16-bit precision
).to("cuda") # GPU에 로드
Lykon/dreamshaper-8
- Hugging Face에서 매우 인기 있는 Stable Diffusion v1.5 기반의 고화질 커스텀 모델로, 개발자 Lykon이 aesthetic tuning, dream-like 효과, 색감, 명암 등 여러 요소를 강화해 만든 모델 시리즈 중 하나입니다. 현재 dreamshaper는 3~8 버전까지 릴리스되어 있으며, 8은 최신 버전 중 하나입니다.
- anime + semi-realistic + fantasy 스타일의 이미지 표현에 강력하며,
- 일반적인 SD 1.5에 비해 다음과 같은 점에서 향상되었습니다.
- 더 부드러운 색감
- 세련된 조명 표현
- 고화질 얼굴/의상 표현
- 다양한 prompt에 대응 가능한 범용성
줄거리 기반 이미지 생성 함수 정의
# 줄거리 기반 이미지 생성 함수 정의
def generate_image(story_text, scene_number):
# 1. 동화 내용을 기반으로 프롬프트 생성 요청
image_prompt = f"""
다음 동화 내용을 기반으로 영어로 AI 그림 프롬프트를 만들어줘.
anime style, masterpiece, pastel color, soft light 포함
{story_text}
[AI 이미지 프롬프트]
"""
messages.append({"role": "user", "content": image_prompt})
ai_prompt = ask_gpt(messages) # ChatGPT API 호출 (별도 구현 필요)
print(f"\n🎨 [장면 {scene_number} 프롬프트]\n", ai_prompt)- 사용자가 입력한 story_text를 기반으로 ChatGPT에게 영어 이미지 프롬프트를 생성하도록 요청합니다.
- "anime style", "pastel color", "soft light"와 같은 키워드는 dreamshaper-8 모델의 미적 특성을 최대한 끌어내기 위한 스타일 지시어입니다.
- ask_gpt(messages)는 OpenAI GPT API를 사용해 응답을 받는 함수입니다.

uploaded = files.upload()
filename = list(uploaded.keys())[0]
scribble_image = load_image(filename).resize((512, 512))
- 사용자는 직접 그린 낙서를 이미지로 업로드합니다.
- 업로드된 이미지는 load_image()를 통해 PIL 이미지 객체로 로드되고, ControlNet의 입력 크기인 (512, 512)로 리사이즈됩니다.
- 이 scribble 이미지가 구조적 제약(condition)으로 작용합니다.

# 3. ControlNet + Stable Diffusion 이미지 생성
output = pipe(
prompt=ai_prompt, # 생성할 텍스트 프롬프트
negative_prompt="lowres, bad anatomy, blurry, ugly, bad hands, extra fingers, poorly drawn, nsfw",
image=scribble_image, # 사용자 scribble 이미지
num_inference_steps=60, # 디퓨전 반복 횟수 (높을수록 고품질)
guidance_scale=12.5, # 텍스트 프롬프트에 대한 반영 강도
controlnet_conditioning_scale=0.8 # 스케치(조건) 반영 강도 (1.0: 완전 따라감)
)
# 4. 결과 출력 및 저장
result = output.images[0]
result.show()
save_name = f"storybook_scene_{scene_number}.png"
result.save(save_name)
print(f"✅ 저장 완료 → {save_name}")| prompt | 생성할 이미지 설명 (CLIP Text Encoder로 인코딩) | — | story 기반으로 생성된 자연어 프롬프트 |
| negative_prompt | 생성 결과에서 피하고 싶은 요소 (주의: 매우 중요!) | 커스텀 가능 | 손가락 오류, 해상도 문제, NSFW 등 방지 |
| image | ControlNet용 구조 제약 (scribble image) | 512×512 PIL 이미지 | 스케치/윤곽 구조 반영 |
| num_inference_steps=60 | Diffusion 반복 횟수. 많을수록 고해상도/자연스러움 | 일반적으로 30~100 |
60은 품질-속도 균형점으로 적절 |
| guidance_scale=12.5 | 텍스트 프롬프트 반영 정도 (Classifier-Free Guidance) | 보통 7~15 | dreamshaper에서 스타일 반영 강조 시 12~13 추천 |
| controlnet_conditioning_scale=0.8 | 구조 제약 반영 강도 (0: 무시 ~ 1.0: 강하게 반영) | 0.5 ~ 1.0 | 0.8은 구조를 존중하되, 너무 얽매이지 않음 |
- guidance_scale ↑ → 텍스트 스타일 강해짐, 디테일 풍부
- controlnet_conditioning_scale ↑ → 구조 충실도 ↑, 자유도 ↓
→ 동화책 생성에서는 아이 스케치를 충분히 반영하되, 스타일 자유도도 남겨야 하기 때문에 0.8이 적절한 절충값입니다.

아이의 그림을 바탕으로 ControlNet Scribble 사용 예시