[머신러닝] 공모전 추천 시스템(2) - chatGPT OpenAI 활용
2025. 2. 28. 21:13ㆍAI & DS/머신러닝
OpenAI 패키지 임포트
import openai # OpenAI 패키지 임포트
import time # 시간 관련 함수 사용을 위해 임포트
# OpenAI API 키 설정
openai.api_key = ${openai-api-key}OpenAI 활용하여, 전처리된 데이터를 '요약' 하기
# 공모전명과 공모전 소개를 요약하여 '요약' 컬럼 생성
def make_new_summary(text1, text2):
while True:
try:
# OpenAI GPT-3.5-turbo 모델을 사용하여 요약 생성
completion = openai.ChatCompletion.create(
model="gpt-3.5-turbo", # 사용할 모델 설정
messages=[
{"role": "system", "content": "해당 공모전의 내용을 10줄 이하 줄글로 요약해줘 "}, # 시스템 역할로 모델에 지시
{"role": "user", "content": f'{text1}, {text2}'} # 사용자 역할로 입력 텍스트 제공
]
)
category = completion['choices'][0]['message']['content'] # 첫 번째 응답의 내용 추출
print(category) # 요약된 내용 출력
return category # 요약된 내용 반환
except openai.error.RateLimitError:
print("Rate limit reached. Waiting for 20 seconds before retrying...")
time.sleep(20) # 20초 대기 후 재시도
except openai.error.OpenAIError as e: # API 에러 처리
print(f"OpenAI API error: {e}")
return None # 오류 발생 시 None 반환# 새로운 열 추가하여 태깅
# 새로운 열 추가하여 태깅
df1['요약2'] = df1.apply(lambda row: make_new_summary(row['공모전명'], row['공모전 소개']), axis=1)
요약된 칼럼을 통하여, 'tagging'하기
# 요약2 칼럼을 보고 태깅을 진행하는 함수
def make_tagging(text):
try:
completion = openai.ChatCompletion.create(
model="gpt-3.5-turbo",
messages=[
{"role": "system", "content": " 해당 공모전의 태깅을 만들어줘. 소프트웨어/서비스, 콘텐츠(게임, 미디어), 프로그래밍/모델링, 해킹/보안, UI/UX/디자인, 데이터분석/문제해결 중에서 무조건 하나만 선택해야하며, 꼭 내가 예시로 든 태그의 구조를 가져야해"},
{"role": "user", "content": text}
]
)
data = completion['choices'][0]['message']['content'] # content 객체만 추출
category = data
print(data) # 태그된 내용 출력
return category
except openai.error.APIError as e:
print(f"OpenAI API returned an API Error: {e}")
time.sleep(120)
except openai.error.APIConnectionError as e:
print(f"Failed to connect to OpenAI API: {e}")
time.sleep(120)
except openai.error.RateLimitError as e:
print(f"OpenAI API request exceeded rate limit: {e}")
time.sleep(120)# 요약을 이용하여 tag 열 추가하여 태깅
df1['tag'] = df1['공모전 소개'].apply(make_tagging)
GPT로 생성한 태깅을 replace를 통해서 정리하기
#replace를 통한 답변 깔끔하게 정리
#GPT가 원하지 않는 유형의 답변을 생성했을 경우
df1['tag'] = df1['tag'].replace({'태깅: 데이터분석/문제해결 ':'데이터분석/문제해결',
'콘테스트의 주제와 내용을 고려해볼 때, 해당 공모전의 태그는 **콘텐츠(게임, 미디어)**로 설정하는 것이 적합해 보입니다.': '콘텐츠(게임, 미디어)',
'태그: 데이터분석/문제해결': '데이터분석/문제해결',
'태그: AI/머신러닝': 'AI/머신러닝',
'태깅 : AI/머신러닝': 'AI/머신러닝',
'태그: 콘텐츠(게임, 미디어)': '콘텐츠(게임, 미디어)',
'태그 : 콘텐츠(게임, 미디어)': '콘텐츠(게임, 미디어)',
'소프트웨어/서비스, 데이터분석/문제해결': '데이터분석/문제해결, 소프트웨어/서비스',
'태그: 데이터분석/문제해결, 소프트웨어/서비스': '데이터분석/문제해결, 소프트웨어/서비스',
'태그: 소프트웨어/서비스' : '소프트웨어/서비스',
'- 소프트웨어/서비스':'소프트웨어/서비스',
'**소프트웨어/서비스**':'소프트웨어/서비스',
'콘텐츠(게임)':'콘텐츠(게임, 미디어)',
'- 데이터분석/문제해결':'데이터분석/문제해결',
'### 데이터분석/문제해결\n':'데이터분석/문제해결',
'태깅 : UI/UX/디자인':'UI/UX/디자인',
'컨텐츠(게임,미디어)':'콘텐츠(게임, 미디어)',
'태그: 프로그래밍/모델링':'프로그래밍/모델링',
'[데이터분석/문제해결]' :'데이터분석/문제해결',
'데이터분석/문제해결, 소프트웨어/서비스':'데이터분석/문제해결',
'콘텐츠(게임,미디어)':'콘텐츠(게임, 미디어)',
'데이터분석/문제해결, 해킹/보안':'데이터분석/문제해결',
'GovTech/공모전':'데이터분석/문제해결'
})
df1['tag'].value_counts()
OpenAI 활용하여, 공모전의 난이도 결정하기
# 난이도 결정 함수
def make_level(text):
try:
# OpenAI GPT-3.5-turbo 모델을 사용하여 난이도 결정
completion = openai.ChatCompletion.create(
model="gpt-3.5-turbo",
messages=[
{"role": "system", "content": "공모전의 난이도를 결과로 출력해줘 난이도는 '상', '중', '하' 중 하나로 형색을 맞춰서 출력해줘"},
{"role": "user", "content": text},
],
temperature=0.5,
)
data = completion.choices[0].message['content'] # 첫 번째 응답의 내용을 추출
print(data) # 결과를 출력 (디버깅용)
return data # 난이도 데이터를 반환
except openai.error.APIError as e:
print(f"OpenAI API returned an API Error: {e}")
time.sleep(120)
except openai.error.APIConnectionError as e:
print(f"Failed to connect to OpenAI API: {e}")
time.sleep(120)
except openai.error.RateLimitError as e:
print(f"OpenAI API request exceeded rate limit: {e}")
time.sleep(120)
# 난이도 열에 태깅
for i in range(len(df1)):
df1['난이도'][i] = make_level(df1['공모전 소개'][i])
GPT로 생성한 난이도를 replace를 통해서 정리하기
#replace를 통한 답변 깔끔하게 정리
#GPT가 원하지 않는 유형의 답변을 생성했을 경우
df1['난이도'] = df1['난이도'].replace({'난이도: 중': '중', '이 문서의 내용은 중 난이도에 해당합니다.': '중', '난이도: 하': '하','': '없음',
'문장이 없기 때문에 난이도를 판단할 수 없습니다. 다른 문장이나 내용을 제공해주시면 더 정확한 난이도 판단을 도와드릴 수 있습니다.': '없음',
'문장이 없어서 난이도를 판단할 수 없습니다. 다시 한 번 문장을 입력해주시겠어요?': '없음',
'문장이 짧고 단순하여 난이도를 평가할 수 없습니다.': '없음',
'죄송합니다, 문장이 없어서 난이도를 판단할 수 없습니다. 다시 한번 문장을 입력해주시겠어요?': '없음',
"이 공모전의 난이도는 '중'입니다.":'중',
"이 공모전의 난이도는 '상'입니다." : '상',
"이 공모전의 난이도는 '중' 입니다.":'중',
"이 공모전은 '중' 난이도의 공모전입니다.":'중',
"공모전의 난이도를 판단하기 위해서는 참가자들이 충족해야 하는 조건, 제출해야 하는 서류의 양 및 내용, 시상 내역 등을 고려해야 합니다. 이러한 정보를 토대로 본 공모전의 난이도를 '중'으로 판단할 수 있습니다. \n\n이유는 다음과 같습니다:\n- 참가 자격이나 제출 조건이 상세히 명시되어 있어서 참가자들이 충분히 이해하고 준비할 수 있음\n- 최우수 아이디어에 대한 멘토링 및 지원이 제공되는 등 참가자들에게 추가적인 지원이 제공되어 창업에 도움이 될 수 있음\n- 상금 규모가 일정 수준 이상으로 제공되어 참가자들에게 동기부여가 될 수 있음\n\n이러한 이유들을 고려할 때, 본 공모전은 '중' 난이도로 판단할 수 있습니다." :'중',
"공모전의 난이도를 판단하기 위해 공모분야, 주제, 시상내역, 제출 형식, 접수 방법, 참고사항 등을 고려해보겠습니다.\n\n주어진 정보에 따르면, 공모분야는 영화와 영상 두 부문으로 나뉘어 있으며, AI나 메타버스 기술이 활용된 작품을 제출해야 합니다. 시상내역은 총 21개의 작품에 총 3,500만원의 상금이 주어지며, 제출 형식은 Full HD 이상급 화질의 mp4 파일로 접수됩니다.\n\n또한, 접수 방법은 유튜브 영상 업로드와 출품신청서 메일 전송으로 이루어지며, AI와 메타버스 기술을 활용할 수 있는 3가지 추천방안이 제공되어 있습니다. 공모전의 홍보 채널은 인스타그램, 페이스북, 카카오채널을 통해 이루어지며, 문의 사항은 영화제 조직위 사무국과 경상북도청 메타버스혁신과로 문의할 수 있습니다.\n\n이러한 정보를 종합해보았을 때, 이 공모전은 주제와 기술적 요구사항이 높은 편이며, AI와 메타버스 기술을 활용하여 창의적이고 혁신적인 작품을 만들어야 합니다. 따라서 이 공모전의 난이도는 '상'으로 판단됩니다." : '상',
"이 외교 공공데이터 활용 경진대회는 '중' 난이도에 해당합니다.":'중',
"이 공모전은 '상' 난이도에 해당합니다.":'상',
"이 공모전은 전북특별자치도 출신 개인 또는 팀을 대상으로 하는 인디게임 공모전으로, 전북 소재 학교 출신도 참여 가능한 점이 좋은 점입니다. 또한, 자유주제의 미출시게임을 제출할 수 있고, 온라인을 통한 간편한 접수가 가능하다는 점이 흥미로운 부분입니다.\n\n난이도는 '중'으로 분류될 수 있습니다. 공모 자격과 공모 대상이 다소 제한적이며, 게임을 개발하고 빌드 파일을 제출해야 하는 점에서 조금의 난이도가 있습니다. 하지만, 공고문과 공모 접수 링크가 명확하게 안내되어 있어 참가자들이 참여하기 쉽다는 점에서 중간 정도의 난이도로 평가할 수 있습니다.":'중',
"이번 (주)영림원소프트랩과 한국경영정보학회 공동 주최하는 2024년 대학생 ERP 아이디어 공모전은 '중' 난이도를 가지고 있습니다.":'중',
"공모전의 난이도는 '하'입니다.":'하',
"상\n\n해커톤의 주최 및 주관이 부산광역시와 (재)부산테크노파크로서 권위 있는 기관들이며, 공공데이터를 활용한 부산지역 현안을 해결하는 목표가 뚜렷하게 제시되어 있습니다. 또한, 상금과 함께 우승팀에게는 DX Camp 참가 특전이 제공된다는 점에서 참가자들에게 다양한 혜택을 제공하는 것으로 보입니다. 이에 해당 공모전은 '상' 난이도로 판단됩니다." : '상'
})
df1['난이도'].value_counts()
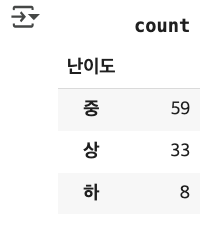
OpenAI 활용하여, 공모전의 기관 종류 결정하기
import openai
import time
openai.api_key = ${openai-api-key}
# 기관 종류를 결정하는 함수
def make_gov(text):
try:
# GPT-3.5-turbo 모델을 사용하여 기관 종류를 결정
completion = openai.ChatCompletion.create(
model="gpt-3.5-turbo",
messages=[
{"role": "system", "content": "You are an assistant that classifies the type of institution (e.g., 공공기관, 사기업, 기타) based on the provided institution name."},
{"role": "user", "content": text},
],
temperature=0.5,
)
data = completion.choices[0].message['content'] # GPT 응답에서 데이터를 추출
return data # 결과 반환
except openai.error.APIError as e:
print(f"OpenAI API returned an API Error: {e}")
time.sleep(120)
except openai.error.APIConnectionError as e:
print(f"Failed to connect to OpenAI API: {e}")
time.sleep(120)
except openai.error.RateLimitError as e:
print(f"OpenAI API request exceeded rate limit: {e}")
time.sleep(120)
# 기관 열에 태깅
for i in range(len(df1)):
df1.at[i, '기관종류'] = make_gov(df1.at[i, '기관명'])
# replace를 통한 답변 깔끔하게 정리
df1['기관종류'] = df1['기관종류'].replace({'기업': '사기업'})
df1['기관종류'] = df1['기관종류'].apply(lambda x: x if x in ['공공기관', '사기업'] else '기타')
# 기관종류 열의 값 빈도수 확인
print(df1['기관종류'].value_counts())
추천 시스템 구현
1. 데이터 전처리
import pandas as pd
import numpy as np
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.preprocessing import MinMaxScaler
from sklearn.metrics.pairwise import cosine_similarity
# 1) api로 태깅까지 완료된 데이터셋을 불러오기
df = pd.read_csv("/content/final.csv")
# 2) '공모전 소개' 열에서 '없음' 또는 null인 행을 삭제하기
# '없음' 문자열과 null 값을 포함하는 행 삭제
df= df[df['공모전 소개'].notna() & (df['공모전 소개'] != '없음')]
# 결과 출력
df
import pandas as pd
# '종료 날짜' 컬럼을 datetime 형식으로 변환
df['시작 날짜'] = pd.to_datetime(df['시작 날짜'], errors='coerce')
# 결과 확인
df['시작 날짜'].dtypes
# '종료 날짜' 컬럼을 datetime 형식으로 변환
df['종료 날짜'] = pd.to_datetime(df['종료 날짜'], errors='coerce')
# 변환이 제대로 되었는지 확인
print(df['종료 날짜'].dtypes)2. 자신이 원하는 조건을 가진 공모전을 추리는 함수 만들기
# 2. 자신의 원하는 조건을 가진 공모전을 추리는 함수 만들기
# 필터링 함수 정의
def filter_contests(df, tag=None, 기관종류=None, 난이도=None):
# 원본을 바꾸지 않기 위해 df 복사
filtered_df = df.copy()
# 조건에 따라 필터링
if tag is not None:
filtered_df = filtered_df[filtered_df['tag'] == tag]
if 기관종류 is not None:
filtered_df = filtered_df[filtered_df['기관종류'] == 기관종류]
if 난이도 is not None:
filtered_df = filtered_df[filtered_df['난이도'] == 난이도]
# 상금에 따라 내림차순으로 정렬
filtered_df = filtered_df.sort_values(by='상금', ascending=False)
return filtered_df
# input 함수 사용하여 각 매개변수마다 입력값 받기
tag_input = input("공모전 종류(tag) : [소프트웨어/서비스, 콘텐츠(게임, 미디어), 프로그래밍/모델링, 해킹/보안, UI/UX/디자인, 데이터분석/문제해결] 중 선택: ")
기관종류_input = input("기관 종류: [공공기관, 사기업, 기타] 중 선택: ")
난이도_input = input("난이도 : [상, 중, 하] 중 선택: ")
# 필터링된 결과 출력
result_df = filter_contests(df, tag=tag_input, 기관종류=기관종류_input, 난이도=난이도_input)
if result_df.empty:
print("조건에 맞는 공모전이 없습니다.")
else:
display(result_df)
3. 필터링된 공모전을 입력값으로 하는 추천시스템 구현하기
필터링 함수 정의 (filter_contests) : 주어진 조건에 따라 공모전 데이터를 필터링
def filter_contests(df, tag=None, 기관종류=None, 난이도=None):
filtered_df = df.copy() # 원본 데이터프레임을 수정하지 않기 위해 복사본을 생성
# 조건에 따라 필터링
if tag is not None:
filtered_df = filtered_df[filtered_df['tag'] == tag]
if 기관종류 is not None:
filtered_df = filtered_df[filtered_df['기관종류'] == 기관종류]
if 난이도 is not None:
filtered_df = filtered_df[filtered_df['난이도'] == 난이도]
# 상금에 따라 내림차순으로 정렬
filtered_df = filtered_df.sort_values(by='상금', ascending=False)
# 인덱스를 0부터 다시 설정
filtered_df = filtered_df.reset_index(drop=True)
return filtered_df
- df.copy()로 원본 데이터프레임을 변경하지 않도록 안전한 복사본을 생성
- 입력된 조건(tag, 기관종류, 난이도)에 따라 필터링을 수행
- sort_values(by='상금', ascending=False)를 통해 상금을 기준으로 내림차순으로 정렬
- reset_index(drop=True)는 인덱스를 다시 0부터 정렬
사용자로부터 입력 받기 : 필터링 기준을 사용자가 입력하도록 유도
tag_input = input("공모전 종류(tag) : [소프트웨어/서비스, 콘텐츠(게임, 미디어), 프로그래밍/모델링, 해킹/보안, UI/UX/디자인, 데이터분석/문제해결] 중 선택: ")
기관종류_input = input("기관 종류: [공공기관, 사기업, 기타] 중 선택: ")
난이도_input = input("난이도 : [상, 중, 하] 중 선택: ")
- 사용자로부터 태그, 기관 종류, 난이도를 입력받습니다. 이 입력값을 이용해 공모전을 필터링합니다.
필터링된 결과 출력 : 필터링 후 결과를 출력
filtered_df = filter_contests(df, tag=tag_input, 기관종류=기관종류_input, 난이도=난이도_input)
if filtered_df.empty:
print("조건에 맞는 공모전이 없습니다.")
else:
display(filtered_df)
- filter_contests 함수를 통해 필터링된 결과를 출력
- 조건에 맞는 공모전이 없으면 "조건에 맞는 공모전이 없습니다."라는 메시지를 출력
- 필터링된 결과가 있으면 display(filtered_df)로 데이터를 출력
추천 시스템 구현 (TF-IDF + Cosine Similarity) : 공모전 이름을 입력받아 관련된 공모전을 추천
TF-IDF 벡터화
tfidf = TfidfVectorizer(stop_words='english')
tfidf_matrix = tfidf.fit_transform(filtered_df['요약2'].fillna(''))
- TfidfVectorizer는 텍스트 데이터를 숫자 벡터로 변환하는 도구
- 여기서는 공모전의 요약 부분을 TF-IDF 방식으로 벡터화
- fillna('')는 NaN 값이 있을 경우 빈 문자열로 대체하여 오류를 방지
- 이렇게 변환된 tfidf_matrix는 각 공모전 요약에 대해 각 단어의 중요도를 포함한 벡터들을 생성
- 이 벡터는 각 문서(공모전 요약)가 단어들로 어떻게 구성되어 있는지 나타냄
TF-IDF (Term Frequency-Inverse Document Frequency)
- TF-IDF는 텍스트에서 중요한 단어나 문장을 추출하는 데 사용하는 기법
- 텍스트 데이터를 벡터 형태로 변환하여, 각 단어가 문서에서 얼마나 중요한지 점수를 매김
TF (Term Frequency)
: 특정 단어가 문서 내에서 얼마나 자주 나타나는지의 빈도 = 특정 단어가 문서에서 등장하는 횟수

IDF (Inverse Document Frequency)
: 특정 단어가 전체 문서 집합에서 얼마나 중요한지 나타내는 값
전체 문서에서 자주 등장하는 단어는 중요도가 낮고, 드물게 등장하는 단어는 중요도가 높음

TF-IDF는 두 값을 결합하여 각 단어의 중요도를 계산
- 자주 등장하는 단어지만 많은 문서에서 등장하는 단어는 중요하지 않다고 판단
- 적게 등장하지만 특정 문서에서 중요한 단어는 더 높은 점수를 부여
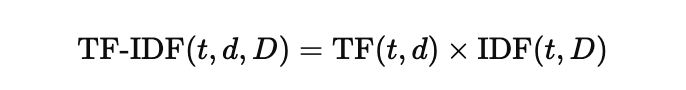
코사인 유사도 계산
cosine_sim = cosine_similarity(tfidf_matrix, tfidf_matrix)- cosine_similarity는 공모전 간의 유사도를 계산
- 두 벡터 간의 코사인 각도를 계산하여 얼마나 유사한지 점수를 매김
Cosine Similarity
- 두 벡터 간의 유사도를 측정하는 방법 -> 벡터가 얼마나 유사한지를 계산하는데, 코사인 각도를 사용
- 두 벡터가 동일한 방향을 가질수록 코사인 유사도는 1에 가까워지며, 반대 방향일수록 -1에 가까워짐
추천 함수 (recommendations) : 주어진 공모전과 유사한 공모전을 추천
def recommendations(df, contest_name, cosine_sim):
if contest_name not in df['공모전명'].values:
print(f"'{contest_name}'이라는 이름의 공모전을 찾을 수 없습니다.")
return
# 공모전명에 해당하는 인덱스 찾기
idx = df[df['공모전명'] == contest_name].index[0]
sim_scores = list(enumerate(cosine_sim[idx]))
sim_scores = sorted(sim_scores, key=lambda x: x[1], reverse=True)
# 자기 자신을 제외
sim_scores = [(i, score) for i, score in sim_scores if i != idx]
# 상위 3개 공모전 선택
sim_scores = sim_scores[:3]
contest_index = [i[0] for i in sim_scores]
recommended_contests = df['공모전명'].iloc[contest_index]
similarity_scores = [i[1] for i in sim_scores]
for i, contest in enumerate(recommended_contests):
print(f"{i+1}. {contest} | Similarity Score: {similarity_scores[i]:.2f}")
- contest_name이 공모전 목록에 없으면 오류 메시지를 출력
- 해당 공모전의 인덱스를 찾고, 그 인덱스를 기준으로 cosine_sim에서 유사한 공모전들을 찾아냄
- 유사도 점수를 내림차순으로 정렬한 뒤, 자기 자신을 제외하고 상위 3개 공모전만 선택하여 추천
- 추천된 공모전 이름과 그에 대한 유사도 점수를 출력
추천 시스템 실행 : 추천 시스템을 실제로 실행하여 공모전 추천 결과를 보여줌
contest_name_input = input("추천받을 공모전의 이름을 입력하세요: ")
recommendations(filtered_df, contest_name_input, cosine_sim)
- 사용자가 추천받고 싶은 공모전의 이름을 입력하고, 그에 대해 추천 결과를 출력
for i, contest in enumerate(recommended_contests):
print(f"{i+1}. {contest} | Similarity Score: {similarity_scores[i]:.2f}")
- 추천된 공모전 이름과 유사도 점수를 출력

'AI & DS > 머신러닝' 카테고리의 다른 글
| [머신러닝] 데이터가 너무 한쪽으로 치우쳐있는 문제 해결하기 - bin/로그 변환/이상치 제거/Box-Cox 변환 (0) | 2025.02.28 |
|---|---|
| [머신러닝] 회귀 모델 - Linear Regression(선형 회귀)/Bagging Regressor(배깅 회귀)/Boosting Regressor(부스팅 회귀) (0) | 2025.02.28 |
| [머신러닝] 하이퍼파라미터 / 최적의 하이퍼파라미터 찾기란 무엇인가? / Random Forest와 하이퍼파라미터 (0) | 2025.02.27 |
| [머신러닝] 분류 학습 예측 모델 - KNN / Random Forest / 3가지 모델의 단점 및 원인 (0) | 2025.02.27 |
| [머신러닝] 분류 학습 모델 - Logistic Regression (0) | 2025.02.27 |